因为想看看random forest,找到了这本书:
Feature Extraction, Foundations and Applications。
拿了第一章,很好的感觉,放在了豆瓣里面。
相关的课程网站在这里。
Saturday, December 29, 2007
Tuesday, December 4, 2007
Friday, November 16, 2007
Notes about SVM & the Kernel Method
Reference:
[1] An Introduction to Support Vector Machines and other kernel-based learning methods
Nello Cristianini, John Shawer-Taylor
[2] 数据挖掘中的新方法-支持向量机
邓乃扬, 田英杰
[3] 机器学习
Tom M. Mitchell
曾华军 张银奎 等译
[4] http://en.wikipedia.org/wiki/Support_vector_machine
[5] An introduction to Kernel-Based Learning Algorithms
Klaus-Robert Muller, Sebastian Mika, Gunnar Ratsch, Koji Tsuda, and Bernhard Scholkopf
----------------------------------------------------------------------------------
Issues:
1.Some background of computational learning theory
Empirical Risk Minimization (ERM)
Probably Approximately Correct Learning (PAC)
--risk function and expected risk ([2] p131)
Vapnik-Chervonenkis dimension
refer:
[1] Chapter4 Generalization Theory
[2] p161 section4.8
[3] chapter seven
*They tend to solve the problem:
*求解分类问题,也许我们会想到如下途径:首先用训练集估计概率分布,然后根据所得到的概率分布求得决策函数。但是这样做违反了利用有限数量心细解决问题的一项基本原则。这项原则就是:在求解一个问题过程中,不应把解决另一个更为一般的问题作为其中的一个步骤。当前求解的问题是分类问题。而概率分布的估计是一个更为一般的问题。事实上,在统计学中,知道了概率分布几乎可以认为知道了一切,因为根据它便能解决各种各样的问题。因此我么内部应该通过估计概率分布而求解分类问题。[2]p141
*学习算法中我们需要选择适当的假设集F。实际上这里的关键因素是假设集F的大小,或F的丰富程度,或者说F的“表达能力”。VC维是对这种“表达能力”的一种描述。
Roughly speaking, the VC dimension measures how many (training) points can be shattered (i.e., separated) for all possible labelings using functions of the class. ([5] section II)
*
2.Optimization Theory
[1] chapter 5
[2] chapter 1
The problems addressed in 1 have a similar form: the hypothesis function should be chosen to minimize (or maximize) a certain functional. Optimization theory is the branch of mathematics concerned with characterizing the solutions of classes of such problems, and developing effective algorithms for finding them.
3. kernel
*Frequently the target concept cannot be expressed as a simple linear combination of the given attributes, but in general requires that more abstract features of the data be exploited. Kernel representations offer alternative solution by projecting the data into a high dimensional feature space to increase the computational power of the linear learning machines. [1]p26
[comment:] "the advantage of using the machines in the dual representation derives from the fact that in this representation the number of tunable parameters does not depend on the number of attributes being used."
-- The number of parameters depends on the definition of the kernel. if you define a "bad" kernel, there will be many parameters as well.
**
With kernels we can compute the linear hyperplane classifier in a Hilbert space with higher dimension. We prefer linear models because:
1) there is the intuition that a "simple" (e.g., linear) function that explains most of the data is preferable to a complex one (Occam's razor). ([5] section II)
2) In practice the bound on the general expected error computed by VC dimension is often neither easily computable nor very helpful. Typical problems are that the upper bound on the expected test error might be trivial (i.e., larger than one), the VC dimension of the function class is unknown or it is infinite (in which case one would need an infinite amount of training data). ([5], section II )
For linear methods, the VC dimension can be estimated as the number of free parameters, but for most other methods (including k-nearest neighbors), accurate estimates for VC-dimension are not available.
3) for the class of hyperplanes the VC dimension itself can be bounded in terms of an other quantity, ther margin. (the margin is defined as trhe minimal distance of a sample to the decision surface) ([5] section II )
4. Existing Kernels
In short, not the mimensionalitybut the complexity of the function class matters. , all one needs for separation is a linear hyperplane. However, it becomes rather tricky to control the feature space for large real-world problems. So even i one could control the statistical complexity of this function class, one would still run into intractability problems while executing an algorithm in this space. Fortunately, for certain feature spaces F and corresponding mapping phai, there is a highly effective trick for computing scalar products in feature spaces using kernel functions. ([5] section II)
[1] An Introduction to Support Vector Machines and other kernel-based learning methods
Nello Cristianini, John Shawer-Taylor
[2] 数据挖掘中的新方法-支持向量机
邓乃扬, 田英杰
[3] 机器学习
Tom M. Mitchell
曾华军 张银奎 等译
[4] http://en.wikipedia.org/wiki/Support_vector_machine
[5] An introduction to Kernel-Based Learning Algorithms
Klaus-Robert Muller, Sebastian Mika, Gunnar Ratsch, Koji Tsuda, and Bernhard Scholkopf
----------------------------------------------------------------------------------
Issues:
1.Some background of computational learning theory
Empirical Risk Minimization (ERM)
Probably Approximately Correct Learning (PAC)
--risk function and expected risk ([2] p131)
Vapnik-Chervonenkis dimension
refer:
[1] Chapter4 Generalization Theory
[2] p161 section4.8
[3] chapter seven
*They tend to solve the problem:
*求解分类问题,也许我们会想到如下途径:首先用训练集估计概率分布,然后根据所得到的概率分布求得决策函数。但是这样做违反了利用有限数量心细解决问题的一项基本原则。这项原则就是:在求解一个问题过程中,不应把解决另一个更为一般的问题作为其中的一个步骤。当前求解的问题是分类问题。而概率分布的估计是一个更为一般的问题。事实上,在统计学中,知道了概率分布几乎可以认为知道了一切,因为根据它便能解决各种各样的问题。因此我么内部应该通过估计概率分布而求解分类问题。[2]p141
*学习算法中我们需要选择适当的假设集F。实际上这里的关键因素是假设集F的大小,或F的丰富程度,或者说F的“表达能力”。VC维是对这种“表达能力”的一种描述。
Roughly speaking, the VC dimension measures how many (training) points can be shattered (i.e., separated) for all possible labelings using functions of the class. ([5] section II)
*
2.Optimization Theory
[1] chapter 5
[2] chapter 1
The problems addressed in 1 have a similar form: the hypothesis function should be chosen to minimize (or maximize) a certain functional. Optimization theory is the branch of mathematics concerned with characterizing the solutions of classes of such problems, and developing effective algorithms for finding them.
3. kernel
*Frequently the target concept cannot be expressed as a simple linear combination of the given attributes, but in general requires that more abstract features of the data be exploited. Kernel representations offer alternative solution by projecting the data into a high dimensional feature space to increase the computational power of the linear learning machines. [1]p26
[comment:] "the advantage of using the machines in the dual representation derives from the fact that in this representation the number of tunable parameters does not depend on the number of attributes being used."
-- The number of parameters depends on the definition of the kernel. if you define a "bad" kernel, there will be many parameters as well.
**
With kernels we can compute the linear hyperplane classifier in a Hilbert space with higher dimension. We prefer linear models because:
1) there is the intuition that a "simple" (e.g., linear) function that explains most of the data is preferable to a complex one (Occam's razor). ([5] section II)
2) In practice the bound on the general expected error computed by VC dimension is often neither easily computable nor very helpful. Typical problems are that the upper bound on the expected test error might be trivial (i.e., larger than one), the VC dimension of the function class is unknown or it is infinite (in which case one would need an infinite amount of training data). ([5], section II )
For linear methods, the VC dimension can be estimated as the number of free parameters, but for most other methods (including k-nearest neighbors), accurate estimates for VC-dimension are not available.
3) for the class of hyperplanes the VC dimension itself can be bounded in terms of an other quantity, ther margin. (the margin is defined as trhe minimal distance of a sample to the decision surface) ([5] section II )
4. Existing Kernels
- Polynomial (homogeneous):
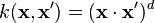
- Polynomial (inhomogeneous):

- Radial Basis Function:
 , for γ > 0
, for γ > 0 - Gaussian Radial basis function:

- Sigmoid:
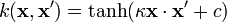 , for some (not every) κ > 0 and c <>
, for some (not every) κ > 0 and c <>
In short, not the mimensionalitybut the complexity of the function class matters. , all one needs for separation is a linear hyperplane. However, it becomes rather tricky to control the feature space for large real-world problems. So even i one could control the statistical complexity of this function class, one would still run into intractability problems while executing an algorithm in this space. Fortunately, for certain feature spaces F and corresponding mapping phai, there is a highly effective trick for computing scalar products in feature spaces using kernel functions. ([5] section II)
Wednesday, October 24, 2007
Latex 公式
from http://blog.sina.com.cn/s/blog_53be544e010003hn.html
首先你要先使用宏包 ntheorem
\usepackage[amsmath,thmmarks]{ntheorem}
% 定理类环境宏包,其中 amsmath 选项
% 用来兼容 AMS LaTeX 的宏包
%=== 配合上面的ntheorem宏包产生各种定理结构,重定义一些
%正文相关标题 ===
\theoremstyle{plain}
\theoremheaderfont{\normalfont\rmfamily\CJKfamily{hei}}
\theorembodyfont{\normalfont\rm\CJKfamily{kai}} \theoremindent0em
\theoremseparator{\hspace{1em}} \theoremnumbering{arabic}
%\theoremsymbol{} %定理结束时自动添加的标志
\newtheorem{definition}{\hspace{2em}定义}[section]
%\newtheorem{definition}{\hei 定义}[section]
%!!!注意当section为中国数字时,[section]不可用!
\newtheorem{proposition}{\hspace{2em}命题}[section]
\newtheorem{property}{\hspace{2em}性质}[section]
\newtheorem{lemma}{\hspace{2em}引理}[section]
%\newtheorem{lemma}[definition]{引理}
\newtheorem{theorem}{\hspace{2em}定理}[section]
\newtheorem{axiom}{\hspace{2em}公理}[section]
\newtheorem{corollary}{\hspace{2em}推论}[section]
\newtheorem{exercise}{\hspace{2em}习题}[section]
\theoremsymbol{$\blacksquare$}
\newtheorem{example}{\hspace{2em}例}[section]
\theoremstyle{nonumberplain}
\theoremheaderfont{\CJKfamily{hei}\rmfamily}
\theorembodyfont{\normalfont \rm \CJKfamily{song}} \theoremindent0em
\theoremseparator{\hspace{1em}} \theoremsymbol{$\blacksquare$}
\newtheorem{proof}{\hspace{2em}证明}
注意:如果你使用的book,而不是article,那么你要把所有的section改为chapter.
首先你要先使用宏包 ntheorem
\usepackage[amsmath,thmmarks]{ntheorem}
% 定理类环境宏包,其中 amsmath 选项
% 用来兼容 AMS LaTeX 的宏包
%=== 配合上面的ntheorem宏包产生各种定理结构,重定义一些
%正文相关标题 ===
\theoremstyle{plain}
\theoremheaderfont{\normalfont\rmfamily\CJKfamily{hei}}
\theorembodyfont{\normalfont\rm\CJKfamily{kai}} \theoremindent0em
\theoremseparator{\hspace{1em}} \theoremnumbering{arabic}
%\theoremsymbol{} %定理结束时自动添加的标志
\newtheorem{definition}{\hspace{2em}定义}[section]
%\newtheorem{definition}{\hei 定义}[section]
%!!!注意当section为中国数字时,[section]不可用!
\newtheorem{proposition}{\hspace{2em}命题}[section]
\newtheorem{property}{\hspace{2em}性质}[section]
\newtheorem{lemma}{\hspace{2em}引理}[section]
%\newtheorem{lemma}[definition]{引理}
\newtheorem{theorem}{\hspace{2em}定理}[section]
\newtheorem{axiom}{\hspace{2em}公理}[section]
\newtheorem{corollary}{\hspace{2em}推论}[section]
\newtheorem{exercise}{\hspace{2em}习题}[section]
\theoremsymbol{$\blacksquare$}
\newtheorem{example}{\hspace{2em}例}[section]
\theoremstyle{nonumberplain}
\theoremheaderfont{\CJKfamily{hei}\rmfamily}
\theorembodyfont{\normalfont \rm \CJKfamily{song}} \theoremindent0em
\theoremseparator{\hspace{1em}} \theoremsymbol{$\blacksquare$}
\newtheorem{proof}{\hspace{2em}证明}
注意:如果你使用的book,而不是article,那么你要把所有的section改为chapter.
Friday, September 7, 2007
Jensen-Shannon divergence
definition given by wikipedia
In probability theory and statistics, the Jensen-Shannon divergence is a popular method of measuring the similarity between two probability distributions.
used as a similarity measure of entities in
Chen, J. and D. Ji, et al. (2006). Relation Extraction Using Label Propagation Based Semi-Supervised Learning. Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia.
In probability theory and statistics, the Jensen-Shannon divergence is a popular method of measuring the similarity between two probability distributions.
used as a similarity measure of entities in
Chen, J. and D. Ji, et al. (2006). Relation Extraction Using Label Propagation Based Semi-Supervised Learning. Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia.
Sunday, August 26, 2007
Lazy Learning
http://en.wikipedia.org/wiki/Lazy_learning
In artificial intelligence, lazy learning is a learning method in which generalization beyond the training data is delayed until a query is made to the system, as opposed to in eager learning, where the system tries to generalize the training data before receiving queries.
...
In artificial intelligence, lazy learning is a learning method in which generalization beyond the training data is delayed until a query is made to the system, as opposed to in eager learning, where the system tries to generalize the training data before receiving queries.
...
Hausdorff distance
what is Hausdorff distance ?
An introduction
Named after Felix Hausdorff (1868-1942), Hausdorff distance is the « maximum distance of a set to the nearest point in the other set »
An introduction
Named after Felix Hausdorff (1868-1942), Hausdorff distance is the « maximum distance of a set to the nearest point in the other set »
Sunday, August 19, 2007
A talk given by Prof. Mitch Marcus on last Friday
> タイトル:Unsupervised induction of morphological structure
>
> 概要:
> We will discuss the problem of unsupervised morphological and part of
> speech (POS) acquisition in realistic settings. From studies of tagged
> corpora, we show that there is a sparse data problem in morphology,
> which raises the question of how rare forms may be learned. We then show
> that it is often the case that the base form of a word is present among
> the different inflections of a lexeme, which suggests that rare forms
> can be learned by association with a base form. We introduce new
> representations for morphological structure which express the
> morphophonological transduction behavior of these base forms, and
> present
> an algorithm to acquire these structures automatically from an unlabeled
> corpus. We apply the algorithm to a range of Indo-European languages
> including Slovene, English, and Spanish.
>
comment:
1. met the same group of people (well, I mean young researchers basically) again.
2. I asked two questions on how to deal with sparse data. Based on what I understood:
a) To prune the space by analyzing features of the data.
b) To add back ground knowledge.
3. Jin said he is the 牛魔王 in their field! Orz...
>
> 概要:
> We will discuss the problem of unsupervised morphological and part of
> speech (POS) acquisition in realistic settings. From studies of tagged
> corpora, we show that there is a sparse data problem in morphology,
> which raises the question of how rare forms may be learned. We then show
> that it is often the case that the base form of a word is present among
> the different inflections of a lexeme, which suggests that rare forms
> can be learned by association with a base form. We introduce new
> representations for morphological structure which express the
> morphophonological transduction behavior of these base forms, and
> present
> an algorithm to acquire these structures automatically from an unlabeled
> corpus. We apply the algorithm to a range of Indo-European languages
> including Slovene, English, and Spanish.
>
comment:
1. met the same group of people (well, I mean young researchers basically) again.
2. I asked two questions on how to deal with sparse data. Based on what I understood:
a) To prune the space by analyzing features of the data.
b) To add back ground knowledge.
3. Jin said he is the 牛魔王 in their field! Orz...
Friday, August 17, 2007
Latex中纵向排列两个子图
引入包subfigure.
\usepackage{subfigure}
使用的时候:
\begin{figure}[tb]
\centering \subfigure[subCaption_1 ]{\includegraphics[width=200pt]{1.eps}}
\label{fig:selFilter} \subfigure[subCaption_2]{\includegraphics[width=200pt]{2.eps}}
\label{fig:tripleQuery}
\caption{Query} \label{Fig:CellDropRates}
\end{figure}
\usepackage{subfigure}
使用的时候:
\begin{figure}[tb]
\centering \subfigure[subCaption_1 ]{\includegraphics[width=200pt]{1.eps}}
\label{fig:selFilter} \subfigure[subCaption_2]{\includegraphics[width=200pt]{2.eps}}
\label{fig:tripleQuery}
\caption{Query} \label{Fig:CellDropRates}
\end{figure}
Tuesday, August 7, 2007
Maxium Likelihood Estimate (MLE)
1. from wikipedia:
Maximum likelihood estimation (MLE) is a popular statistical method used to make inferences about parameters of the underlying probability distribution from a given data set. That is to say, you have a sample of data
X_{1}, \dots, X_{n} \!
and some kind of model for data, and you want to estimate parameters of the distribution.
2. from http://www.itl.nist.gov/div898/handbook/eda/section3/eda3652.htm
Maximum likelihood estimation begins with the mathematical expression known as a likelihood function of the sample data. Loosely speaking, the likelihood of a set of data is the probability of obtaining that particular set of data given the chosen probability model. This expression contains the unknown parameters. Those values of the parameter that maximize the sample likelihood are known as the maximum likelihood estimates.
the dis/advantages are discussed, as well as the software.
3. about smoothed maximum likelihood estimates.
One purpose of the smoothed estimates is too account for sparseness in counts for distributions with a lot of history by backing off to less sparse estimates.
(McDonald, R. (2005). Extracting Relations from Unstructured Text, Department of Computer and Information Science, University of Pennsylvania.)
Maximum likelihood estimation (MLE) is a popular statistical method used to make inferences about parameters of the underlying probability distribution from a given data set. That is to say, you have a sample of data
X_{1}, \dots, X_{n} \!
and some kind of model for data, and you want to estimate parameters of the distribution.
2. from http://www.itl.nist.gov/div898/handbook/eda/section3/eda3652.htm
Maximum likelihood estimation begins with the mathematical expression known as a likelihood function of the sample data. Loosely speaking, the likelihood of a set of data is the probability of obtaining that particular set of data given the chosen probability model. This expression contains the unknown parameters. Those values of the parameter that maximize the sample likelihood are known as the maximum likelihood estimates.
the dis/advantages are discussed, as well as the software.
3. about smoothed maximum likelihood estimates.
One purpose of the smoothed estimates is too account for sparseness in counts for distributions with a lot of history by backing off to less sparse estimates.
(McDonald, R. (2005). Extracting Relations from Unstructured Text, Department of Computer and Information Science, University of Pennsylvania.)
Sunday, July 22, 2007
Conditional Random Fields (CRFs)
from
http://www.inference.phy.cam.ac.uk/hmw26/crf/
Conditional random fields (CRFs) are a probabilistic framework for labeling and segmenting structured data, such as sequences, trees and lattices. The underlying idea is that of defining a conditional probability distribution over label sequences given a particular observation sequence, rather than a joint distribution over both label and observation sequences. The primary advantage of CRFs over hidden Markov models is their conditional nature, resulting in the relaxation of the independence assumptions required by HMMs in order to ensure tractable inference. Additionally, CRFs avoid the label bias problem, a weakness exhibited by maximum entropy Markov models (MEMMs) and other conditional Markov models based on directed graphical models. CRFs outperform both MEMMs and HMMs on a number of real-world tasks in many fields, including bioinformatics, computational linguistics and speech recognition.
tutorial:
Hanna M. Wallach. Conditional Random Fields: An Introduction. Technical Report MS-CIS-04-21. Department of Computer and Information Science, University of Pennsylvania, 2004.
http://www.inference.phy.cam.ac.uk/hmw26/crf/
Conditional random fields (CRFs) are a probabilistic framework for labeling and segmenting structured data, such as sequences, trees and lattices. The underlying idea is that of defining a conditional probability distribution over label sequences given a particular observation sequence, rather than a joint distribution over both label and observation sequences. The primary advantage of CRFs over hidden Markov models is their conditional nature, resulting in the relaxation of the independence assumptions required by HMMs in order to ensure tractable inference. Additionally, CRFs avoid the label bias problem, a weakness exhibited by maximum entropy Markov models (MEMMs) and other conditional Markov models based on directed graphical models. CRFs outperform both MEMMs and HMMs on a number of real-world tasks in many fields, including bioinformatics, computational linguistics and speech recognition.
tutorial:
Hanna M. Wallach. Conditional Random Fields: An Introduction. Technical Report MS-CIS-04-21. Department of Computer and Information Science, University of Pennsylvania, 2004.
Tuesday, July 10, 2007
Semantics, Syntax and pragmatics
from: Semantic Tagging - Susanne Ekeklint
--------------
The difference between syntactic tagging and semantic tagging is that the categories that are used to mark the entities in the latter case are of a semantic kind. Semantics has to do with intentions and meanings. POS tagging may sometimes be considered semantic but is usually seen as syntactic tagging. By tradition there is a separation between the form side (syntax) and the content side (semantics) of a phrase and the intention of this is to make a distinction between what is being said to how it is being said. Levison (1983) describes the historical background of the terms syntax, semantics and pragmatics by referring to Charles Morries's(1971) distinctions, within the sudy of "the relations of signs", or semiotics.
Syntactics (or syntax) being the study of "the formal relation of signs to one another", semantics the study of "the relations of signs to the objects to which the signs are applicable" (their designata), and pragmatics, the study of "the relation of signs to interpreters". (Morris 1938:6, quoted in Levinson 1938:1)
Levinson says that there is a "pure study" in each one of the three ares; it is however a known fact that in practice the areas often overlaps. Semantics includes the study of syntax and pragmatics includes the study of semantics (Allwood, 1993)
--------------
Levinson Stephen C.(1983) Pragmatics. Cambridge University Press
Morris, Charles W. (1971) Writings on the General Theory of Signs. The Hague: Mouton.
Morris 1938:6
--------------
The difference between syntactic tagging and semantic tagging is that the categories that are used to mark the entities in the latter case are of a semantic kind. Semantics has to do with intentions and meanings. POS tagging may sometimes be considered semantic but is usually seen as syntactic tagging. By tradition there is a separation between the form side (syntax) and the content side (semantics) of a phrase and the intention of this is to make a distinction between what is being said to how it is being said. Levison (1983) describes the historical background of the terms syntax, semantics and pragmatics by referring to Charles Morries's(1971) distinctions, within the sudy of "the relations of signs", or semiotics.
Syntactics (or syntax) being the study of "the formal relation of signs to one another", semantics the study of "the relations of signs to the objects to which the signs are applicable" (their designata), and pragmatics, the study of "the relation of signs to interpreters". (Morris 1938:6, quoted in Levinson 1938:1)
Levinson says that there is a "pure study" in each one of the three ares; it is however a known fact that in practice the areas often overlaps. Semantics includes the study of syntax and pragmatics includes the study of semantics (Allwood, 1993)
--------------
Levinson Stephen C.(1983) Pragmatics. Cambridge University Press
Morris, Charles W. (1971) Writings on the General Theory of Signs. The Hague: Mouton.
Morris 1938:6
Sunday, July 1, 2007
The slide about text catgorization
Mainly about the content of the chapter 16 of the book Foundations of Statistical Natural Language Processing
Here is the slide.
Here is the slide.
Sunday, June 17, 2007
Generative Model and Disriminative Model
==
Ref: MLWiki
A generative model is one which explicitly states how the observations are assumed to have been generated. Hence, it defines the joint probability of the data and latent variables of interest.

==
See also: Generative Model from wikipedia.
==
ref: A simple comparison
of
generative model (model likelihood and prior) <-- NB..
and discriminative model (model posterior) <-- SVM
==
ref: Classify Semantic Relations in Bioscience Texts.
Generative models learn the prior probability of the class and the probability of the features given the class; they are the natural choice in cases with hidden variables (partially observed or missing data). Since labeled data is expensive to collect, these models may be useful when no labels are available. However, in this paper we test the generative models on fully observed data and show that , although not as accurate as the discriminative model, their performance is promising enough to encourage their use for the case of partially observed data.
Discriminative models learn the probability of the class given the features. When we have fully observed data and we just need to learn the mapping from features to classes(classification), a discriminative approach may be more appropriate.
It must be pointed out that the neural network (discriminative model) is much slower than the graphical models (HMM-like generative models), and requires a great deal of memory.
Ref: MLWiki
A generative model is one which explicitly states how the observations are assumed to have been generated. Hence, it defines the joint probability of the data and latent variables of interest.
==
See also: Generative Model from wikipedia.
==
ref: A simple comparison
of
generative model (model likelihood and prior) <-- NB..
and discriminative model (model posterior) <-- SVM
==
ref: Classify Semantic Relations in Bioscience Texts.
Generative models learn the prior probability of the class and the probability of the features given the class; they are the natural choice in cases with hidden variables (partially observed or missing data). Since labeled data is expensive to collect, these models may be useful when no labels are available. However, in this paper we test the generative models on fully observed data and show that , although not as accurate as the discriminative model, their performance is promising enough to encourage their use for the case of partially observed data.
Discriminative models learn the probability of the class given the features. When we have fully observed data and we just need to learn the mapping from features to classes(classification), a discriminative approach may be more appropriate.
It must be pointed out that the neural network (discriminative model) is much slower than the graphical models (HMM-like generative models), and requires a great deal of memory.
Wednesday, June 6, 2007
Collocations
Chap 5 of foundations of statistical natural language processing
- a collocation is an expression consisting of two or more words that correspond to some conventional say of saying things.
- Collocations are characterized by limited compositionality.
(we call a natural language expression compositional if the meaning of the expression can be predicted from the meaning of the parts.)
Collocations are note fully compositional in that there is usually an element of meaning added to the combination.
--> non-compositionality
--> non-substitutability
--> non-modifiability
-term: the word term has a different meaning in information retrieval. There it refers to both words and phrases.
- a number of approaches to finding collocations:
a)selections by frequency,
raw frequency doesn't work.
With part of speech tag patterns, one gets surprisingly good result.<-- Justeson and Katz' method. hints: a simple quantitative technique combined with a small amount of linguistic knowledge goes a longway.
works well for fixed phrases.
b)selection based on mean and variance of the distance between focal word collocating word
scenario: the distance between two words in not constant so a fixed phrase approach would not work.
collocational window (usually a window of 3 to 4 words on each side fo a word)
Mean and variance o the offsets between two words in a corpus.
c)hypothesis testing (********)
in b) we can not make for sure that the high frequency and low variance of two words can be accidental. So we are also taking into account how much data we have seen. Even if there is a remarkable pattern, we will discount it if we haven't seen enough data to be certain that it couldn't be due to chance.
-->null hypothesis.
-->t test : assume that the probabilities are approximately normally distributed.
The t test looks at the mean and variance of a sample of measurements, where the null hypothesis is that the sample is drawn from a distribution with mean miu. The test looks at the difference between the observed and expected means, scaled by the variance of the data, and tells us how likely one is to get a sample of that mean and variance ( or a more extreme mean and variance) assuming that the sample is drawn from a normal distribution with mean miu.
(todo)
--> Chi-square test
The essence of the test is to compare the observed frequencies in the table with the frequencies expected for independence. If the difference between observed and expected frequencies is large, then we can eject the null hypothesis of independence.
d)mutual information
--> likelihood ratios:
more appropriate for sparse data than the chi-square test
- a collocation is an expression consisting of two or more words that correspond to some conventional say of saying things.
- Collocations are characterized by limited compositionality.
(we call a natural language expression compositional if the meaning of the expression can be predicted from the meaning of the parts.)
Collocations are note fully compositional in that there is usually an element of meaning added to the combination.
--> non-compositionality
--> non-substitutability
--> non-modifiability
-term: the word term has a different meaning in information retrieval. There it refers to both words and phrases.
- a number of approaches to finding collocations:
a)selections by frequency,
raw frequency doesn't work.
With part of speech tag patterns, one gets surprisingly good result.<-- Justeson and Katz' method. hints: a simple quantitative technique combined with a small amount of linguistic knowledge goes a longway.
works well for fixed phrases.
b)selection based on mean and variance of the distance between focal word collocating word
scenario: the distance between two words in not constant so a fixed phrase approach would not work.
collocational window (usually a window of 3 to 4 words on each side fo a word)
Mean and variance o the offsets between two words in a corpus.
c)hypothesis testing (********)
in b) we can not make for sure that the high frequency and low variance of two words can be accidental. So we are also taking into account how much data we have seen. Even if there is a remarkable pattern, we will discount it if we haven't seen enough data to be certain that it couldn't be due to chance.
-->null hypothesis.
-->t test : assume that the probabilities are approximately normally distributed.
The t test looks at the mean and variance of a sample of measurements, where the null hypothesis is that the sample is drawn from a distribution with mean miu. The test looks at the difference between the observed and expected means, scaled by the variance of the data, and tells us how likely one is to get a sample of that mean and variance ( or a more extreme mean and variance) assuming that the sample is drawn from a normal distribution with mean miu.
(todo)
--> Chi-square test
The essence of the test is to compare the observed frequencies in the table with the frequencies expected for independence. If the difference between observed and expected frequencies is large, then we can eject the null hypothesis of independence.
d)mutual information
--> likelihood ratios:
more appropriate for sparse data than the chi-square test
Controlled Language
What are Controlled Natural Languages?
"Controlled Natural Languages are subsets of natural languages whose grammars and dictionaries have been restricted in order to reduce or eliminate both ambiguity and complexity. Traditionally, controlled languages fall into two major categories: those that improve readability for human readers, particularly non-native speakers, and those that improve computational processing of the text."
[link]
"Controlled Natural Languages are subsets of natural languages whose grammars and dictionaries have been restricted in order to reduce or eliminate both ambiguity and complexity. Traditionally, controlled languages fall into two major categories: those that improve readability for human readers, particularly non-native speakers, and those that improve computational processing of the text."
[link]
Friday, May 18, 2007

Sunday, May 6, 2007
更改latex 中item的样子
\renewcommand{\labelitemi}{$\star$}
e.g.change the "dot" to "-"
\renewcommand{\labelitemi}{-}
\begin{itemize}
\item aaaaaa
\item bbbbbbb
\end{itemize}
\end{definition}
e.g.change the "dot" to "-"
\renewcommand{\labelitemi}{-}
\begin{itemize}
\item aaaaaa
\item bbbbbbb
\end{itemize}
\end{definition}
Examples of Math

from Information Retrieval in Folksonomies: Search and Ranking
Andreas Hotho, Robert Jaschke, Christoph Schmitz, Gerd Stumme
Saturday, May 5, 2007
Thursday, May 3, 2007
Latex并列子图中使用minipage
\begin{figure}[htb]
\centering \mbox{
\subfigure[title for sub figure 1]{
\begin{minipage}[c]{3.7cm}
\small
a sentence\\
a sentence\\
\end{minipage}
\label{fig:labelOfSubFigureA}
}\quad
\subfigure[title for sub figure b]{
\begin{minipage}[c]{3.7cm}
\small
\\
a sentence\\
a sentence\\
\end{minipage}
\label{fig:tripleTagsB} }
} \caption{Triple tags}
\label{fig:label for sub figure B}
\end{figure}
--------------------------------------
e.g.

\centering \mbox{
\subfigure[title for sub figure 1]{
\begin{minipage}[c]{3.7cm}
\small
a sentence
\label{fig:labelOfSubFigureA}
}\quad
\subfigure[title for sub figure b]{
\begin{minipage}[c]{3.7cm}
\small
a sentence\\
\label{fig:tripleTagsB} }
} \caption{Triple tags}
\label{fig:label for sub figure B}
\end{figure}
--------------------------------------
e.g.

Wednesday, May 2, 2007
latex中输入定义
\documentclass[times, 10pt,twocolumn]{article}
....
\usepackage{amsmath,amsthm,amssymb} % 引入 AMS 數學環境g
....
\newtheorem{definition}{Definition}
\newtheorem{theorem}{Theorem}(for 公理)
\begin{document}
...
(如果只是definition,之用引入amssymb包)
\begin{definition}[Name of the Definition]
content of the definition
\end{definition}
....
....
\usepackage{amsmath,amsthm,amssymb} % 引入 AMS 數學環境g
....
\newtheorem{definition}{Definition}
\newtheorem{theorem}{Theorem}(for 公理)
\begin{document}
...
(如果只是definition,之用引入amssymb包)
\begin{definition}[Name of the Definition]
content of the definition
\end{definition}
....
Monday, April 30, 2007
About RDF query
1. http://www.w3.org/2001/11/13-RDF-Query-Rules/
This document provides a survey of RDF query language and implementations and describes their capabilities in terms described in RDF Query and Rules Framework.
2.SPARQL: A query platform for Web 2.0 and the Semantic Web
A full list of different query language implementations can bee seen at http://www.w3.org/2001/11/13-RDF-Query-Rules/. But these languages lack both a common syntax and a common semantics. In fact, the existing query languages cover a significant semantic range: from declarative, SQL-like languages, to path languages, to rule or production-like systems. And SPARQL had to fill this gap.
This document provides a survey of RDF query language and implementations and describes their capabilities in terms described in RDF Query and Rules Framework.
2.SPARQL: A query platform for Web 2.0 and the Semantic Web
A full list of different query language implementations can bee seen at http://www.w3.org/2001/11/13-RDF-Query-Rules/. But these languages lack both a common syntax and a common semantics. In fact, the existing query languages cover a significant semantic range: from declarative, SQL-like languages, to path languages, to rule or production-like systems. And SPARQL had to fill this gap.
Wednesday, April 25, 2007
Monday, April 9, 2007
about Kernel method
tutorial on kernel method
Bernhard Schölkopf. Statistical learning and kernel methods. MSR-TR 2000-23, Microsoft Research, 2000.
Kernel methods retain te original representation of objects and use the object in algorithms only via computing a kernel function between a pair of objects. A kernel function is a similarity function satisfying certain properties. More precisely, a kernel function K over the object space X is binary function K:X*X ->[0, infinite] mapping a pair of objects x,y \in X to their similarity score K(x,y). A kernel function is required to be symmetric and positive-semidefinite.
Bernhard Schölkopf. Statistical learning and kernel methods. MSR-TR 2000-23, Microsoft Research, 2000.
Kernel methods retain te original representation of objects and use the object in algorithms only via computing a kernel function between a pair of objects. A kernel function is a similarity function satisfying certain properties. More precisely, a kernel function K over the object space X is binary function K:X*X ->[0, infinite] mapping a pair of objects x,y \in X to their similarity score K(x,y). A kernel function is required to be symmetric and positive-semidefinite.
Monday, April 2, 2007
NOTE: enable curl extension from PHP
出处在这里
版本:php5.05
@已经内置有php_curl.dll,在ext目录下,此DLL用于支持SSL和zlib.
@在php.ini中找到有extension=php_curl.dll, 去掉前面的注释.
@设置extension_dir=c:\php\ext,
@将:libeay32.dll, ssleay32.dll, php5ts.dll, php_curl.dll 都拷贝到system32目录下 (或将这些文件的目录加入系统的path变量中)
@重启apache/IIS即可.
----------------------------------
查看curl的版本:
<? php
print_r(curl_version());
?>
版本:php5.05
@已经内置有php_curl.dll,在ext目录下,此DLL用于支持SSL和zlib.
@在php.ini中找到有extension=php_curl.dll, 去掉前面的注释.
@设置extension_dir=c:\php\ext,
@将:libeay32.dll, ssleay32.dll, php5ts.dll, php_curl.dll 都拷贝到system32目录下 (或将这些文件的目录加入系统的path变量中)
@重启apache/IIS即可.
----------------------------------
查看curl的版本:
<? php
print_r(curl_version());
?>
Thursday, March 29, 2007
Saturday, March 24, 2007
最近做的事情
0.考虑了一下triple模型的表达能里和局限。涉及:
a) svo
b) event
1.参加T-FaNT。给自己的启发不小。大概考虑了一下自己的试验领域和评价方法。
2. 找了三个parser搭后台环境
a) syntex parser - charniak
http://www.cfilt.iitb.ac.in/~anupama/charniak.php
b) dependency parser
minipar: http://www.cs.ualberta.ca/~lindek/minipar.htm
connexor: http://www.connexor.com/software/
minipar里面的std库和我的不一样。在windows和linux下面链接均未果。又分别找了五个朋友帮忙在他们的环境里链接一次。只有那个越南的同学编译成功了。汗。结果我就写信跟作者要源代码。当然自己也知道不是很可能。抱着万一成功的想法碰碰运气而已。
同时在想connexor的办法。到上周五终于拿到了他们做的协议,让老板签字然后fax过去。希望能够周一拿到,配置完毕。
3.搭建一个client / server的环境。
DN人很好,提供了一台机器可以拿来当服务器。虽然配置不是很高。但是作为服务肯定是够了。但是我们实验室的ip虽然是静态的,被配置成不能作为服务器使用。只有内网机器可以互相访问apache/tomcat服务。
听起来结论很简单对吧?绕了多少弯子花了多少时间,自己做了多少试验才搞清楚他们到底是不是真的是这样配置的。恨死了。要是没有语言问题,简简单单肯定很早就搞定了。所以现在基本上还是在一台机器上同时做客户端和服务器。自给自足。
4.所以要了connexor parser的windows版。我很想要linux版的。但是因为没有静态可外部访问的ip。只好要了windows版的,这其中的原因,苦不堪言……
这说明即使以后我搞到了可访问的静态ip,我的服务器还是得基于windows的……很不高级的样子,而且这样一来那个小小的机器能不能跑动就是个问题了。哀。走一步看一步吧。
5.跟老板谈了一下自己的时间安排。
-----------------------------------------------
给老师发个会议list。
下面:
模型
代码和
试验。
a) svo
b) event
1.参加T-FaNT。给自己的启发不小。大概考虑了一下自己的试验领域和评价方法。
2. 找了三个parser搭后台环境
a) syntex parser - charniak
http://www.cfilt.iitb.ac.in/~anupama/charniak.php
b) dependency parser
minipar: http://www.cs.ualberta.ca/~lindek/minipar.htm
connexor: http://www.connexor.com/software/
minipar里面的std库和我的不一样。在windows和linux下面链接均未果。又分别找了五个朋友帮忙在他们的环境里链接一次。只有那个越南的同学编译成功了。汗。结果我就写信跟作者要源代码。当然自己也知道不是很可能。抱着万一成功的想法碰碰运气而已。
同时在想connexor的办法。到上周五终于拿到了他们做的协议,让老板签字然后fax过去。希望能够周一拿到,配置完毕。
3.搭建一个client / server的环境。
DN人很好,提供了一台机器可以拿来当服务器。虽然配置不是很高。但是作为服务肯定是够了。但是我们实验室的ip虽然是静态的,被配置成不能作为服务器使用。只有内网机器可以互相访问apache/tomcat服务。
听起来结论很简单对吧?绕了多少弯子花了多少时间,自己做了多少试验才搞清楚他们到底是不是真的是这样配置的。恨死了。要是没有语言问题,简简单单肯定很早就搞定了。所以现在基本上还是在一台机器上同时做客户端和服务器。自给自足。
4.所以要了connexor parser的windows版。我很想要linux版的。但是因为没有静态可外部访问的ip。只好要了windows版的,这其中的原因,苦不堪言……
这说明即使以后我搞到了可访问的静态ip,我的服务器还是得基于windows的……很不高级的样子,而且这样一来那个小小的机器能不能跑动就是个问题了。哀。走一步看一步吧。
5.跟老板谈了一下自己的时间安排。
-----------------------------------------------
给老师发个会议list。
下面:
模型
代码和
试验。
Thursday, March 22, 2007
Saturday, March 17, 2007
Thursday, March 8, 2007
Dependency Parsing
Ref:
A Fundamental Algorithm for Dependency Parsing
Notes of Content:
A Fundamental Algorithm for Dependency Parsing
Notes of Content:
- 1. phrase-structure (constituency) parser v.s. dependency parsing.
- 2. constituency grammar v.s. dependency grammar.
- 3. Dependency tree:
- if two words are connected by a dependency relation:they are head and dependent, connected by the link
- in the dependency tree, constituents (phrases) still exist.
- 4. year of 1965, it is proved that dependency grammar and constituency grammar are strongly equivalent - that they can generate the same sentences and make the same structural claims about them - provided the constituency grammar is restricted in a particular way.
Wednesday, March 7, 2007
Introduction to Syntactic Parsing
Introduction to Syntactic Parsing
A good introduction for the beginners.
by Roxana Girju
Novermber 18, 2004
A good introduction for the beginners.
by Roxana Girju
Novermber 18, 2004
Tuesday, March 6, 2007
Five basic sentence patterns in English
First of all, thanks to Jin for his help
Reference 1
Reference 2
Reference 3
-----------------------
From reference 2.
"
Now, I'm sure you know that there are five basic sentence patterns, consisting of necessay elements which are S(subject), V(verb), O(object), and C(complement).
I list out the 5 patterns here:
S+V
S+V+C
S+V+O
S+V+O+C
S+V+O+O
"
Reference 1
Reference 2
Reference 3
-----------------------
From reference 2.
"
Now, I'm sure you know that there are five basic sentence patterns, consisting of necessay elements which are S(subject), V(verb), O(object), and C(complement).
I list out the 5 patterns here:
S+V
S+V+C
S+V+O
S+V+O+C
S+V+O+O
"
Wednesday, February 28, 2007
Good starting point
A new start, although comes a little bit late. But so much better than never.
Today I talked with professor and was told I *can* decide to work on the topic he assigned or the one I have been wanting to do for so long.
But the bad news is, seems it's difficult for a foreigner with little knowledge of Japanese to find a research position in Japan...wow....
Today I talked with professor and was told I *can* decide to work on the topic he assigned or the one I have been wanting to do for so long.
But the bad news is, seems it's difficult for a foreigner with little knowledge of Japanese to find a research position in Japan...wow....
Saturday, February 17, 2007
Friday, February 16, 2007
latex中插入并列子图
使用graphicx宏包和subfigure宏包。下面是一个例子。
\begin{figure}[htb]
\centering
\mbox{
\subfigure[信元丢失率与加速因子之间的关系]{\includegraphics[scale=1.0]{temp1.e
ps}}\quad
\subfigure[信元丢失率与缓冲大小之间的关系]{\includegraphics[scale=1.0]{temp2.e
ps}}
}
\caption{影响信元丢失率的因素}
\label{Fig:CellDropRates}
\end{figure}
\begin{figure}[htb]
\centering
\mbox{
\subfigure[信元丢失率与加速因子之间的关系]{\includegraphics[scale=1.0]{temp1.e
ps}}\quad
\subfigure[信元丢失率与缓冲大小之间的关系]{\includegraphics[scale=1.0]{temp2.e
ps}}
}
\caption{影响信元丢失率的因素}
\label{Fig:CellDropRates}
\end{figure}
Thursday, February 15, 2007
harmonic series and Riemann Zeta Function
>>Harmonic series: sigma (1/n) n = 0 .. infinit

>>Riemann Zeta Function
the most common form of Riemann Zeta Function:

>>

>>Riemann Zeta Function
the most common form of Riemann Zeta Function:
>>

Monday, January 29, 2007
inf (glb) and sup
from mathforum
inf means "infimum," or "greatest lower bound." This is
slightly different from minimum in that the greatest lower bound is
defined as:
x is the infimum of the set S [in symbols, x = inf (S)] iff:
a) x is less than or equal to all elements of S
b) there is no other number larger than x which is less than or equal
to all elements of S.
Basically, (a) means that x is a lower bound of S, and (b) means that
x is greater than all other lower bounds of S.
This differs from min (S) in that min (S) has to be a member of S.
Suppose that S = {2, 1.1, 1.01, 1.001, 1.0001, 1.00001, ...}. This
set has no smallest member, no minimum. However, it's trivial to show
that 1 is its infimum; clearly all elements are greater than or equal
to 1, and if we thought that something greater than 1 was a lower
bound, it'd be easy to show some member of S which is less than it.
So that's the difference between inf and min. It's worth noting that
every set has an inf (assuming minus infinity is okay), and that the
two concepts are the same for finite sets.
glb is another way of writing inf (sort for "greatest lower bound")
------------------------
sup and lub, which are short for "supremum" and "least upper bound."
inf means "infimum," or "greatest lower bound." This is
slightly different from minimum in that the greatest lower bound is
defined as:
x is the infimum of the set S [in symbols, x = inf (S)] iff:
a) x is less than or equal to all elements of S
b) there is no other number larger than x which is less than or equal
to all elements of S.
Basically, (a) means that x is a lower bound of S, and (b) means that
x is greater than all other lower bounds of S.
This differs from min (S) in that min (S) has to be a member of S.
Suppose that S = {2, 1.1, 1.01, 1.001, 1.0001, 1.00001, ...}. This
set has no smallest member, no minimum. However, it's trivial to show
that 1 is its infimum; clearly all elements are greater than or equal
to 1, and if we thought that something greater than 1 was a lower
bound, it'd be easy to show some member of S which is less than it.
So that's the difference between inf and min. It's worth noting that
every set has an inf (assuming minus infinity is okay), and that the
two concepts are the same for finite sets.
glb is another way of writing inf (sort for "greatest lower bound")
------------------------
sup and lub, which are short for "supremum" and "least upper bound."
Saturday, January 20, 2007
Latent Semantic Index (LSI)
1) here is a great explaination to a layman.
or latent semantic analysis
"The term ’semantics’ is applied to the science and study of meaning in language, and the meaning of characters, character strings and words. Not just the language and words themselves, but the true meaning being conveyed in the context in which they are being used.
In 2002 a company called Applied Semantics, an innovator in the use of semantics in text processing, launched a program known as AdSense, which was a form of contextual advertising whereby adverts were placed on website pages which contained text that was relevant to the subject of the adverts.
The matching up of text and adverts was carried out by software in the form of mathematical formulae known as algorithms. It was claimed that these formulae used semantics to analyze the meaning of the text within the web page. In fact, what it initially seemed to do was to match keywords within the page with keywords used in the adverts, though some further interpretation of meaning was evident in the way that some relevant adverts were correctly placed without containing the same keyword character string as used on the web page.
"
2)from Patterns in Unstructured Data -Discovery, Aggregation, and Visualization
or latent semantic analysis
"The term ’semantics’ is applied to the science and study of meaning in language, and the meaning of characters, character strings and words. Not just the language and words themselves, but the true meaning being conveyed in the context in which they are being used.
In 2002 a company called Applied Semantics, an innovator in the use of semantics in text processing, launched a program known as AdSense, which was a form of contextual advertising whereby adverts were placed on website pages which contained text that was relevant to the subject of the adverts.
The matching up of text and adverts was carried out by software in the form of mathematical formulae known as algorithms. It was claimed that these formulae used semantics to analyze the meaning of the text within the web page. In fact, what it initially seemed to do was to match keywords within the page with keywords used in the adverts, though some further interpretation of meaning was evident in the way that some relevant adverts were correctly placed without containing the same keyword character string as used on the web page.
"
2)from Patterns in Unstructured Data -Discovery, Aggregation, and Visualization
Subscribe to:
Posts (Atom)
