[1] An Introduction to Support Vector Machines and other kernel-based learning methods
Nello Cristianini, John Shawer-Taylor
[2] 数据挖掘中的新方法-支持向量机
邓乃扬, 田英杰
[3] 机器学习
Tom M. Mitchell
曾华军 张银奎 等译
[4] http://en.wikipedia.org/wiki/Support_vector_machine
[5] An introduction to Kernel-Based Learning Algorithms
Klaus-Robert Muller, Sebastian Mika, Gunnar Ratsch, Koji Tsuda, and Bernhard Scholkopf
----------------------------------------------------------------------------------
Issues:
1.Some background of computational learning theory
Empirical Risk Minimization (ERM)
Probably Approximately Correct Learning (PAC)
--risk function and expected risk ([2] p131)
Vapnik-Chervonenkis dimension
refer:
[1] Chapter4 Generalization Theory
[2] p161 section4.8
[3] chapter seven
*They tend to solve the problem:
*求解分类问题,也许我们会想到如下途径:首先用训练集估计概率分布,然后根据所得到的概率分布求得决策函数。但是这样做违反了利用有限数量心细解决问题的一项基本原则。这项原则就是:在求解一个问题过程中,不应把解决另一个更为一般的问题作为其中的一个步骤。当前求解的问题是分类问题。而概率分布的估计是一个更为一般的问题。事实上,在统计学中,知道了概率分布几乎可以认为知道了一切,因为根据它便能解决各种各样的问题。因此我么内部应该通过估计概率分布而求解分类问题。[2]p141
*学习算法中我们需要选择适当的假设集F。实际上这里的关键因素是假设集F的大小,或F的丰富程度,或者说F的“表达能力”。VC维是对这种“表达能力”的一种描述。
Roughly speaking, the VC dimension measures how many (training) points can be shattered (i.e., separated) for all possible labelings using functions of the class. ([5] section II)
*
2.Optimization Theory
[1] chapter 5
[2] chapter 1
The problems addressed in 1 have a similar form: the hypothesis function should be chosen to minimize (or maximize) a certain functional. Optimization theory is the branch of mathematics concerned with characterizing the solutions of classes of such problems, and developing effective algorithms for finding them.
3. kernel
*Frequently the target concept cannot be expressed as a simple linear combination of the given attributes, but in general requires that more abstract features of the data be exploited. Kernel representations offer alternative solution by projecting the data into a high dimensional feature space to increase the computational power of the linear learning machines. [1]p26
[comment:] "the advantage of using the machines in the dual representation derives from the fact that in this representation the number of tunable parameters does not depend on the number of attributes being used."
-- The number of parameters depends on the definition of the kernel. if you define a "bad" kernel, there will be many parameters as well.
**
With kernels we can compute the linear hyperplane classifier in a Hilbert space with higher dimension. We prefer linear models because:
1) there is the intuition that a "simple" (e.g., linear) function that explains most of the data is preferable to a complex one (Occam's razor). ([5] section II)
2) In practice the bound on the general expected error computed by VC dimension is often neither easily computable nor very helpful. Typical problems are that the upper bound on the expected test error might be trivial (i.e., larger than one), the VC dimension of the function class is unknown or it is infinite (in which case one would need an infinite amount of training data). ([5], section II )
For linear methods, the VC dimension can be estimated as the number of free parameters, but for most other methods (including k-nearest neighbors), accurate estimates for VC-dimension are not available.
3) for the class of hyperplanes the VC dimension itself can be bounded in terms of an other quantity, ther margin. (the margin is defined as trhe minimal distance of a sample to the decision surface) ([5] section II )
4. Existing Kernels
- Polynomial (homogeneous):
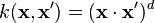
- Polynomial (inhomogeneous):

- Radial Basis Function:
 , for γ > 0
, for γ > 0 - Gaussian Radial basis function:

- Sigmoid:
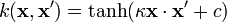 , for some (not every) κ > 0 and c <>
, for some (not every) κ > 0 and c <>
In short, not the mimensionalitybut the complexity of the function class matters. , all one needs for separation is a linear hyperplane. However, it becomes rather tricky to control the feature space for large real-world problems. So even i one could control the statistical complexity of this function class, one would still run into intractability problems while executing an algorithm in this space. Fortunately, for certain feature spaces F and corresponding mapping phai, there is a highly effective trick for computing scalar products in feature spaces using kernel functions. ([5] section II)
